Hi! I'm a software engineer at Zipline, where I work on behavior planning software for autonomous medical delivery drones. I previously worked at SpaceX, where I led software development for fairing recovery as well as their laser-based inter-satellite communication system. I am interested in the development of autonomous systems in the real world, particularly in real-time environments with limited computational resources.
In 2017 I graduated with an M.S. in Computer Science from Stanford University, where I did research on reinforcement learning at the Stanford Intelligent Systems Laboratory. In May 2015 I earned a double B.S. in Computer Science and Electrical and Computer Engineering from Cornell University. In the past, I have interned at SpaceX as an embedded systems firmware developer and at Cisco as a software developer, and have conducted undergraduate computer architecture research at Cornell's Computer Systems Laboratory.
Projects I have worked on outside of work span domains from FPGA development to natural language understanding. Click the project titles to read the reports -- author names are in alphabetical order. Be sure to check out the demo videos!
Pol Rosello, Mykel Kochenderder
International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2018
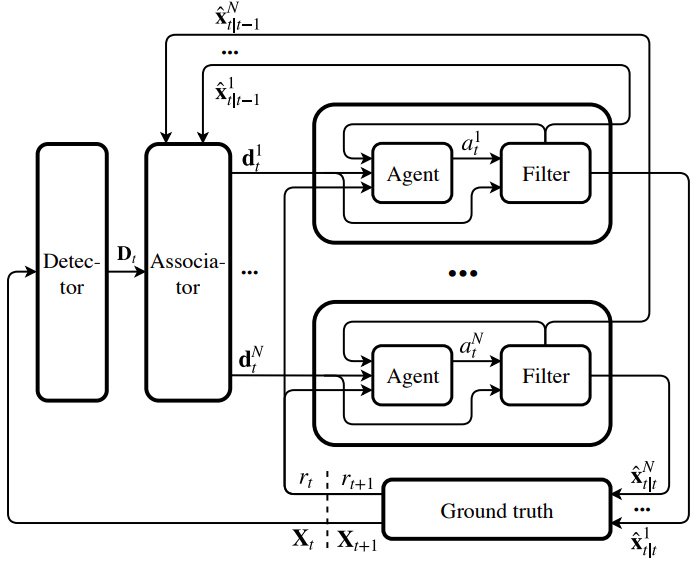
We present a novel, multi-agent reinforcement learning formulation of multi-object tracking that treats creating, propagating, and terminating object tracks as actions in a sequential decision-making problem. Our experiments show an improvement in tracking accuracy over similar state-of-the-art, rule-based approaches on a popular multi-object tracking dataset.
Pol Rosello, Pamela Toman, Nipun Agarwala
CS 224S - Natural Language Processing with Deep Learning, Stanford, Spring 2017
Top 3 CS 224S Paper
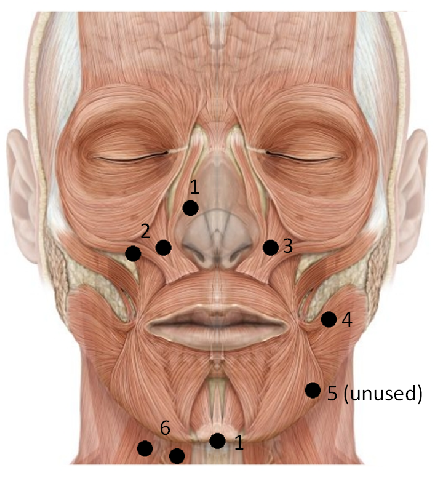
Subvocalization is a phenomenon observed while subjects read or think, characterized by involuntary facial and laryngeal muscle movements. By measuring this muscle activity using surface electromyography (EMG), it may be possible to perform automatic speech recognition (ASR) and enable silent, hands-free human-computer interfaces. In our work, we describe the first approach toward end-to-end, session-independent subvocal speech recognition by leveraging character-level recurrent neural networks (RNNs) and the connectionist temporal classification loss (CTC).
Vincent-Pierre Berges, Isabel Bush, Pol Rosello
CS 224N - Natural Language Processing with Deep Learning, Stanford, Winter 2017
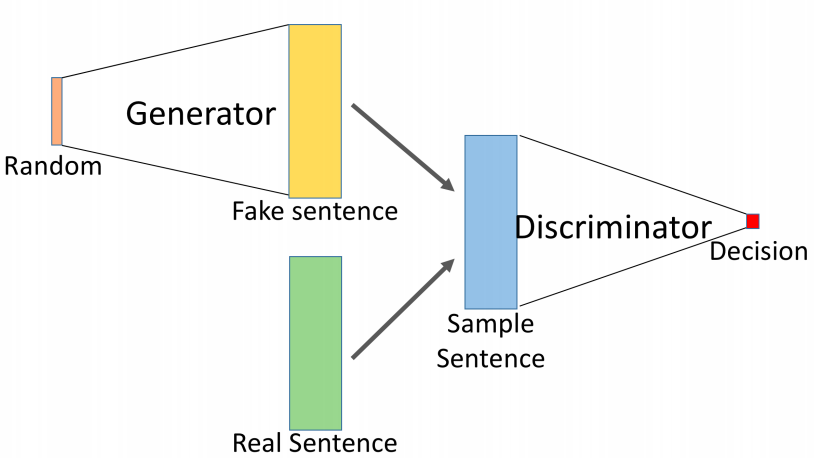
We show the limitations of using language models in a generative manner by training discriminator models to distinguish between real and synthetic text produced by language models. Our best discriminative model reaches 90% accuracy on the test set, demonstrating the weaknesses of using language models as generators. We propose the use of generative adversarial networks (GANs) to improve synthetic text generation. We describe architectural changes to recurrent language models that are necessary for their use in GANs, and pre-train these generative architectures using variational auto-encoders.
Pol Rosello, Alex Tamkin, Alex Martinez
CS 273B - Deep Learning in Genomics and Biomedicine , Stanford, Fall 2016
We use stacked bidirectional LSTMs to impute missing statistics in genome-wide association (GWA) studies. GWA studies correlate single-nucleotide polymorphisms (SNPs) with complex traits by aggregating summary association statistics across many individuals. In our experiment involving the imputation of missing p-values across approximately one million SNPs and 11 traits, our method reduces the mean-squared logarithmic error on imputed p-values by 22.5% when compared to traditional statistical imputation techniques.
Pol Rosello
CS 238 - Decision Making Under Uncertainty, Stanford, Fall 2016
Winner: Top 3 CS 238 Papers Award
Formalized fully-nested interactive POMDPs, a method for optimizing a player's policy in a turn-based, partially-observable game against an unknown rational opponent. Motivated fully-nested I-POMDPs by introducing the game of partially-observable nim, reducing it to a POMDP, and solving it using SARSOP. Showed empirically that increasing the level of a fully-nested I-POMDP does not become intractable for this game.
Gus Liu, Pol Rosello, Ellen Sebastian
CS 224u - Natural Language Understanding, Stanford, Spring 2016
We investigate the problem of style transfer: Given a document D in a style S, and a separate style S', can we produce a new document D' in style S' that preserves the meaning of D? We describe a novel style transfer approach that does not rely on parallel or pseudo-parallel corpora, making use of anchoring-based paraphrase extraction and recurrent neural language models. Language models implemented in Torch7.

Pol Rosello, Cheng-Han Wu, Jiayu Wu
CS 231a - Computer Vision: From 3D Reconstruction to Recognition, Stanford, Spring 2016
Implemented a virtual reality system that achieves the illusion of depth on an ordinary display, requiring no special equipment other than a webcam and a computer. The display simulates motion parallax and a changing field of view, functioning as a virtual "window" into a 3D scene. We use Haar cascade classifiers, camera models, and Kalman filtering to track the user's head in 3D in real time and update the display according to an off-axis projection model. We extend our system with a gesture recognition pipeline that allows for object or scene orbiting. Uses OpenCV and OpenGL. Demo video.

Pol Rosello
CS 231n - Convolutional Neural Networks for Visual Recognition, Stanford, Winter 2016
Designed and trained a fully-convolutional neural network to predict future optical flow from a single video frame. Extended the pipeline with iterative frame warping to generate video predictions in raw pixel space. Implemented in Torch7 and trained on AWS. Demo video.

Taylor Pritchard, Pol Rosello, Frank Xie
ECE 5760 - Advanced Microcontroller Design, Cornell, Spring 2015
Developed an FPGA-based automatic table tennis score keeper, implemented fully in hardware logic without the use of a CPU. By analyzing a video feed of a live game, the system awards points in real time with no direct user input. The project has been featured on Hackaday and the October 2015 issue of IEEE Computer Magazine. Check out our demo video!
Batten Research Group, Cornell, Spring/Fall 2014
Wrote and optimized algorithms in C/C++ to benchmark a novel high-performance, energy-efficient parallel computing microarchitecture by mapping them to a research ISA. Contributions acknowledged in two accepted 2014 IEEE MICRO papers (1, 2) authored by the group.

Power Systems Subteam
Violet Project Team, Cornell, Fall 2013
Programmed and debugged the command and data handling board of a high-agility nanosatellite set to launch in 2017. The board serves as the satellite's central router and interfaces with the flight computer, radio, and numerous sensors such as a gyroscope, a spectrometer and a star tracker.

Cornell University, Fall 2014
Cornell University, Spring 2014
Cornell University, Fall 2013
- CS 234 - Reinforcement Learning
- CS 224S - Spoken Language Processing
- CS 224N - Natural Language Processing with Deep Learning
- CS 238 - Decision Making Under Uncertainty
- CS 157 - Logic and Automated Reasoning
- CS 273B - Deep Learning in Genomics and Biomedicine
- CS 224U - Natural Language Understanding
- CS 231A - Comp. Vision: 3D Reconstruction to Recognition
- CS 231N - Conv. Neural Networks for Visual Recognition
- CS 246 - Mining Massive Data Sets
- CS 243 - Program Analysis and Optimizations
- CS 149 - Parallel Computing
- CS 4820 - Introduction to Analysis of Algorithms
- CS 4852 - Networks II
- ECE 4250 - Digital Signal and Image Processing
- ECE 5760 - Advanced Microcontroller Design
- CS 2850 - Networks
- CS 4410 - Operating Systems
- CS 4780 - Machine Learning
- ECE 3100 - Probability and Inference
- ECE 4450 - Computer Networks and Telecommunications
- ECE 4760 - Design with Microcontrollers
- COGST 1101 - Introduction to Cognitive Science
- ECE 3150 - Introduction to Microelectronics
- ECE 3400 - ECE Practice and Design
- ECE 4271 - Evolutionary Algorithms and Games
- CS 3110 - Data Structures and Functional Programming
- CS 4420 - Computer Architecture
- CS 4700 - Foundations of Artificial Intelligence
- CS 4701 - Practicum in Artificial Intelligence
- ECE 3250 - Mathematics of Signal and System Analysis
- BIONB 2220 - Introduction to Neuroscience
- ECE 2200 - Signals and Systems
- ECE 3140 - Embedded Systems
- CS 2110 - OO Programming and Data Structures
- CS 2800 - Discrete Structures
- ECE 2300 - Digital Logic and Computer Organization
- ECE 2100 - Introduction to Circuits